
Many companies rush to add AI features into their products, expecting immediate competitive advantage. Yet once those systems reach production, the AI operational cost often becomes far larger than the initial development budget. The real expense of AI does not come from building a model prototype. It comes from running the system continuously: compute resources, inference workloads, data pipelines, monitoring infrastructure, and ongoing optimization.
A growing number of technology leaders now recognize that the real challenge is not building AI, but operating AI at scale. According to McKinsey’s Global AI Survey, over 44% of organizations report cost overruns when deploying AI systems into production environments (McKinsey, 2024).
Why AI Operational Cost Is Often Underestimated
Most product teams estimate AI costs based on development time. In reality, AI operational cost grows dramatically after deployment, when real user traffic triggers continuous inference workloads. Several structural factors make AI systems expensive to run.
1. Compute resources required for inference
Unlike traditional backend services, AI models require heavy compute resources every time they generate results.
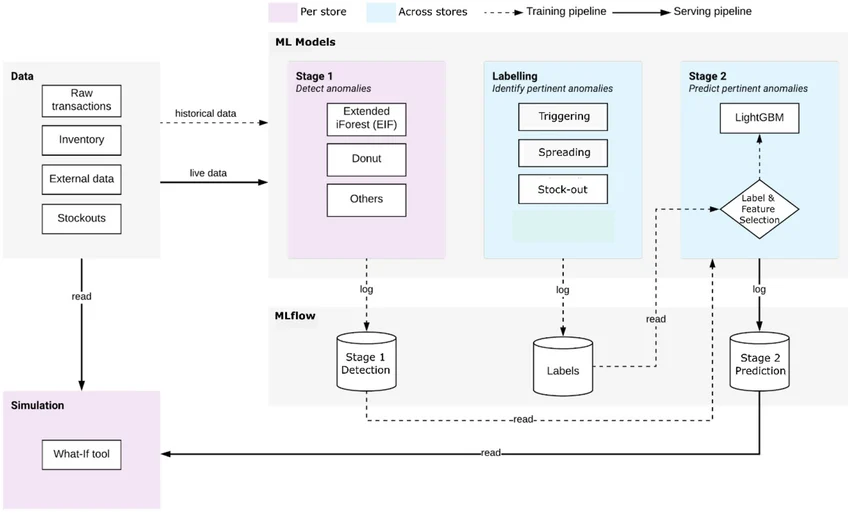
Example of an AI production pipeline integrating data ingestion, anomaly detection models, labeling workflows, and prediction stages (Source: Google Cloud Architecture Center)
Typical operational expenses include:
- GPU or high-performance CPU clusters
- Model inference workloads
- Memory usage for large models
- Latency optimization infrastructure
Large language model inference can cost significantly more than typical API calls. Research from Stanford’s AI Index Report shows that LLM inference costs can increase infrastructure spending by 3–7× compared to traditional backend services (Stanford AI Index, 2024).
2. Data pipelines and continuous training
AI systems require constant data updates to maintain accuracy. Operational pipelines often include:
- Data ingestion and cleaning
- Feature engineering pipelines
- Continuous retraining workflows
- Model evaluation and validation
These pipelines create ongoing infrastructure requirements. According to Gartner, over 85% of AI projects fail to move into production due to operational complexity and data pipeline challenges (Gartner, 2023).
3. Monitoring, governance, and reliability systems
Once AI features affect real users, companies must monitor model behavior in production.
Operational systems typically include:
- Model drift detection
- Bias monitoring
- Performance analytics
- Fallback mechanism
Without these layers, AI outputs can degrade over time and introduce operational risk.
AI Deployment Challenges That Increase Operational Cost
Even when infrastructure is properly planned, AI deployment challenges can increase operational cost dramatically if architecture decisions are not optimized early.
The most common operational mistakes include:
- Over-provisioning GPU resources without workload optimization
- Running large models where smaller models would perform adequately
- Inefficient data pipelines that increase storage and compute usage
- Lack of observability tools for monitoring model performance
These issues create long-term operational inefficiencies. Another hidden cost driver is engineering time. Maintaining AI systems requires specialized expertise across several domains:
- machine learning engineering
- data engineering
- infrastructure management
- model evaluation and governance
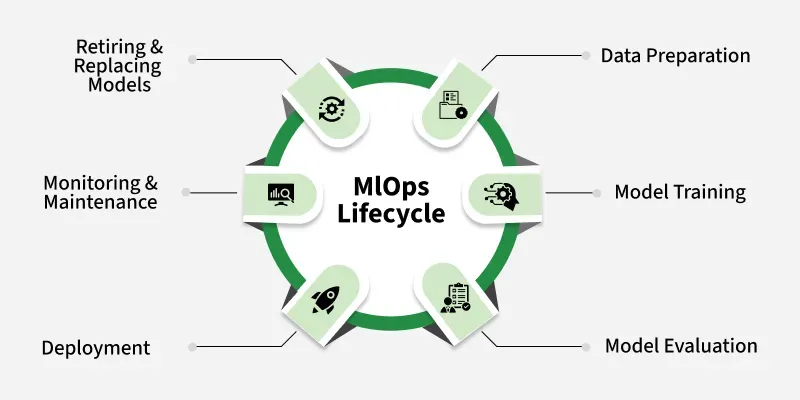
MLOps lifecycle illustrates how AI models move from data preparation to deployment, monitoring, and replacement in production environments (Source: MLOps Community)
According to PwC’s AI Business Survey, companies deploying AI solutions report that operational management accounts for up to 60% of total AI lifecycle cost (PwC, 2024). This explains why many organizations struggle to scale AI features sustainably.
Designing AI Systems With Sustainable Operational Cost
Forward-thinking engineering teams now design AI architecture with cost efficiency as a primary constraint rather than an afterthought. A sustainable AI deployment strategy often includes several architectural principles.
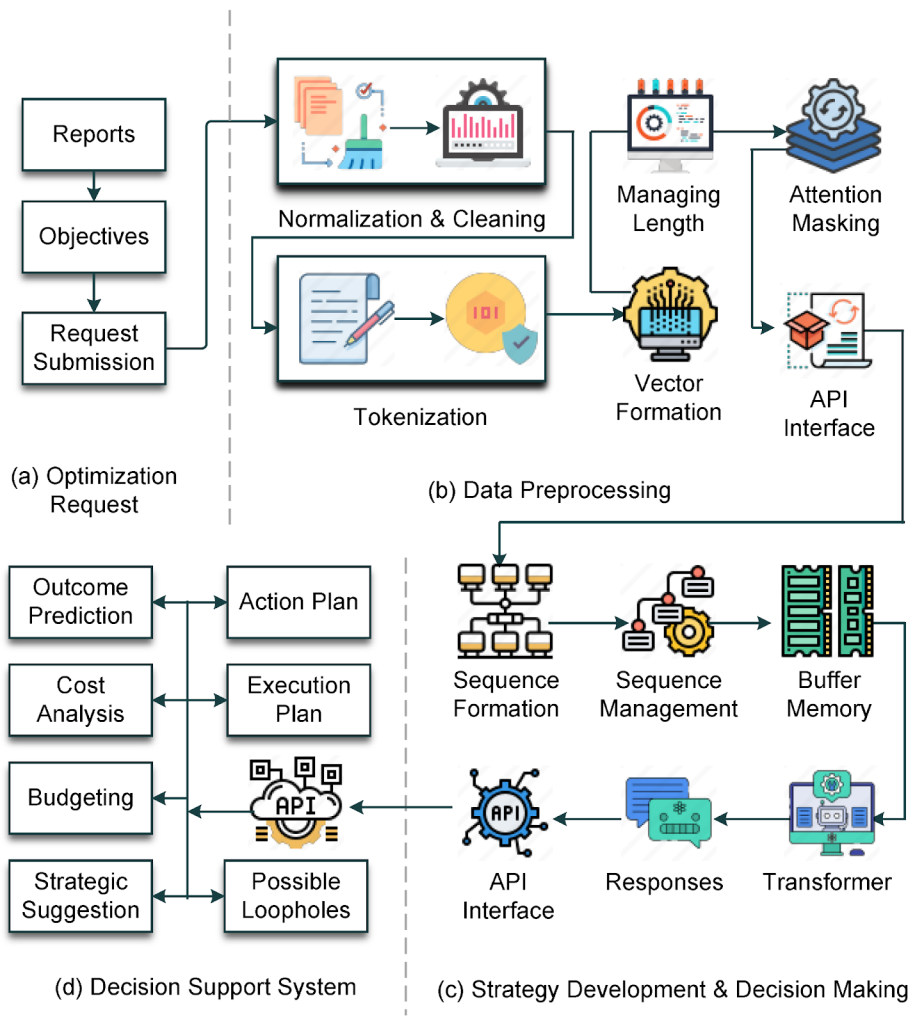
Example architecture of an AI processing pipeline, including data preprocessing, transformer inference, and decision-support integration (Source: IEEE Research on AI system pipelines)
1. Model selection optimization
Instead of defaulting to the largest model available, teams increasingly adopt:
- smaller specialized models
- hybrid model architectures
- retrieval-augmented generation pipelines
These approaches significantly reduce LLM operations cost while maintaining performance.
2. Inference efficiency strategies
Infrastructure optimization techniques include:
- model quantization
- batching inference requests
- GPU utilization optimization
- caching frequently requested outputs
These techniques can reduce operational spending significantly.
3. Use-case driven AI deployment
Rather than embedding AI across every product feature, successful companies deploy AI selectively in areas where measurable ROI exists.
Typical high-ROI use cases include:
- customer support automation
- intelligent search systems
- fraud detection models
- workflow automation tools
Focusing on well-defined use cases prevents unnecessary AI infrastructure expansion.
Why AI Architecture Design Determines Long-Term Cost
The difference between an expensive AI system and a sustainable one usually comes down to architecture decisions made early in development.
Organizations that plan operational architecture early typically implement:
- scalable model serving infrastructure
- efficient data pipelines
- observability systems for model performance
- cost monitoring across AI workloads
Without these systems, AI deployments often become difficult to scale economically. Engineering teams increasingly treat AI systems as long-term infrastructure components, similar to databases or distributed backend services. This mindset shift is essential for controlling AI operational cost as products grow.
Conclusion
The excitement around AI features often hides a deeper operational reality. The real challenge of AI adoption lies not in training models, but in running them reliably and efficiently at scale. Compute resources, inference workloads, data pipelines, and model lifecycle management all contribute to the true AI operational cost that many companies underestimate during early development.
Organizations that approach AI deployment strategically, focusing on architecture design, infrastructure efficiency, and use-case driven implementation, are far more likely to capture the long-term value of AI without uncontrolled operational spending.
AI adoption succeeds when systems are designed for real operational scale, not just prototype performance. Twendee helps organizations design cost-efficient AI architectures, optimize inference infrastructure and deploy AI features aligned with measurable business ROI.
Discover how we supports scalable AI systems: https://twendeesoft.com/Read the latest article: AI Is Moving Faster Than Organizations Can Adapt



